Introduction
As usual, you can find the code for this specific article here
If you've ever used Google Maps, you've definitely struggled to decide where to go to eat. The UI ... frankly sucks beyond belief for an application that has all the data and compute that it has.
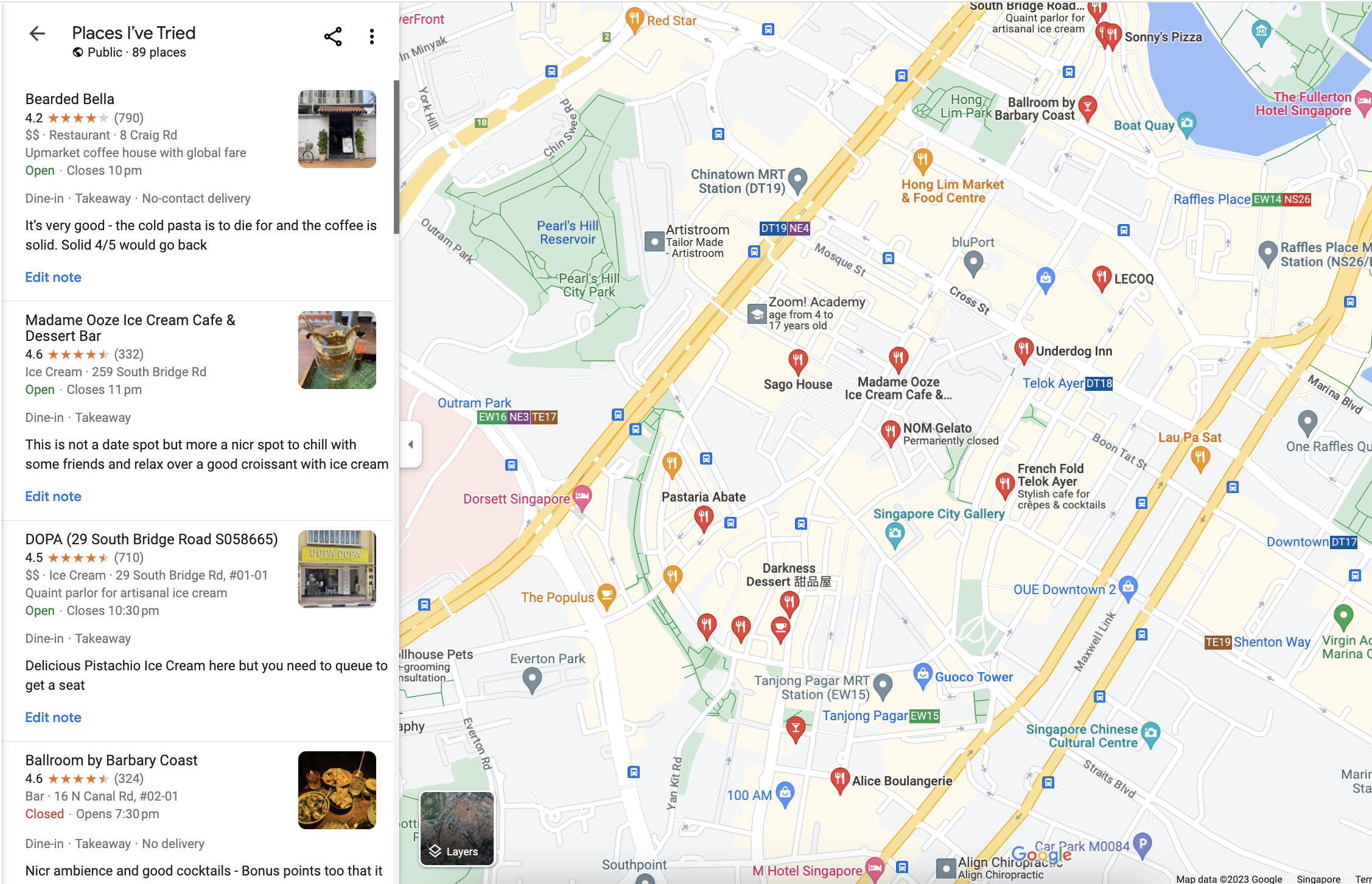
There's not even a simple way to filter the saved places by keywords, categories or even just the location. You need to manually pan and find something that you like.
So i thought I'd crawl it for the fun of it since I wanted more control over my data. I'd seen some jupyter notebooks but no fine-grained script online so I built my own.
The Idea
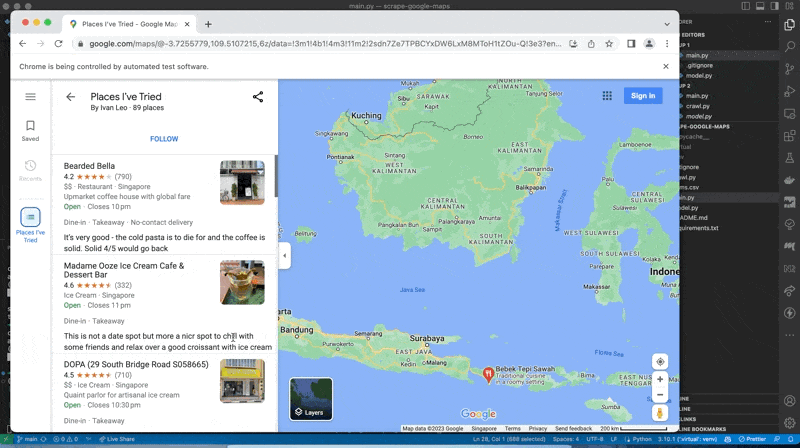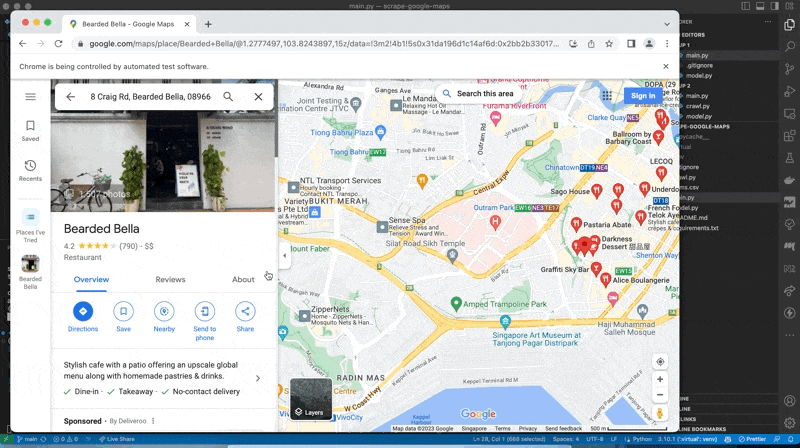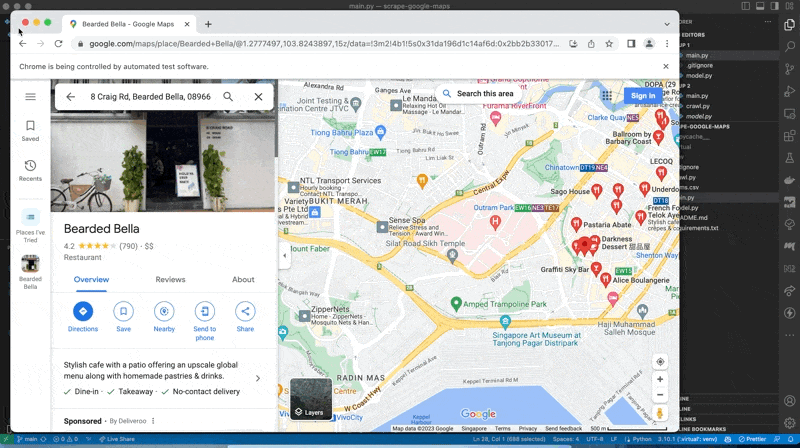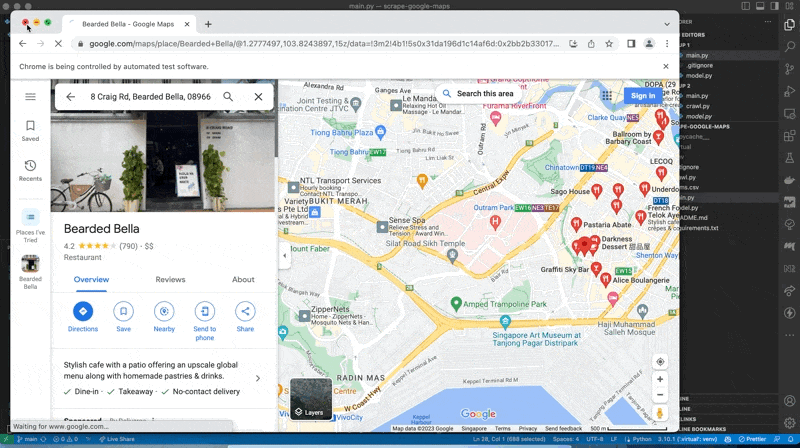
When you navigate to a saved location, you see the following
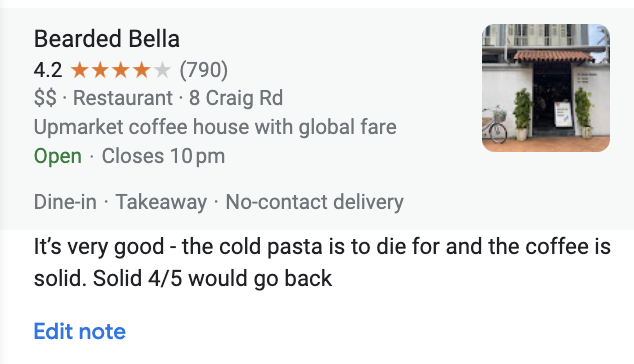
You get
- The name
- The overall rating
- A category that google has assigned to it
among a few other bits of data. But if you use some of the default categories, the amount of data provided is inconsistent. Therefore, here's how our script gets around inconsistent data.
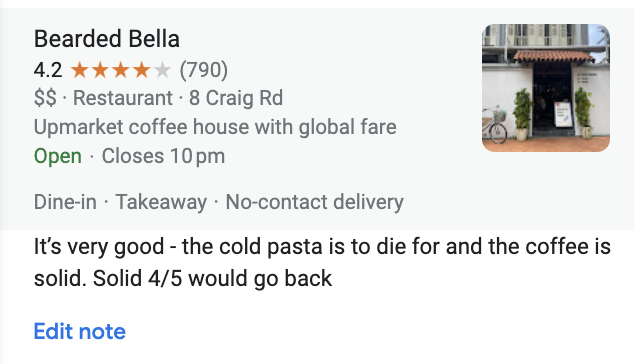
We simply visit the page that's linked to the listing!
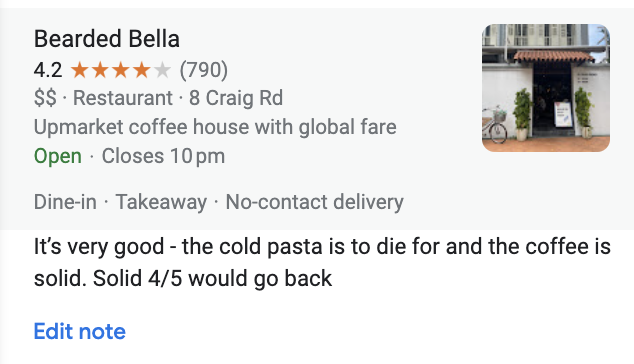
What makes it even better is that the page link itself contains a lot of valuable information
For instance, take the following link to FiftyFive Coffe Bar,
https://www.google.com/maps/place/FiftyFive+Coffee+Bar/@1.3731958,103.8075006,12z/data=!4m11!1m3!11m2!2s9wJ7F7C-bjteOlxRQli8-lZz7jeYIw!3e2!3m6!1s0x31da192386bddc8d:0xed0fef7eae8bf927!8m2!3d1.2795647!4d103.8425105!15sCgEqkgEEY2FmZeABAA!16s%2Fg%2F11k50kg36w?entry=ttu
We can actually extract out things like the lattitude and longtitude from the link. This helps us to perform useful tasks such as geocoding and reverse geocoding.
Even the HTML isn't too bad for scrapping with unique class names that we can target as seen below
The Code
Data Models
Before we start coding out any code, let's start by defining some models
class Status(Enum):
CLOSED = "Closed"
TEMPORARILY_CLOSED = "Temporarily Closed"
OPEN = "Open"
class Listing(BaseModel):
title: str
rating: Optional[float]
number_of_reviews: Optional[int]
address: Optional[str]
review: str
hasDelivery: bool
hasTakeaway: bool
hasDineIn: bool
category: Optional[str]
status: str
url: str
address: str
long: float
lat: floatStatus class is an enumeration that represents the status of a listing. It has three possible values: CLOSED, TEMPORARILY_CLOSED, and OPEN.
The Listing class is a Pydantic model that defines the structure and validation rules for the data related to a specific listing. The fields in this model include:
title: The title of the listing (a string)rating: The rating of the listing (a float, optional)number_of_reviews: The number of reviews for the listing (an integer, optional)address: The address of the listing (a string, optional)review: A review for the listing (a string)hasDelivery: A boolean indicating if the listing offers deliveryhasTakeaway: A boolean indicating if the listing offers takeawayhasDineIn: A boolean indicating if the listing offers dine-incategory: The category of the listing (a string, optional)status: The status of the listing, which should be one of theStatusenumeration values (a string)url: The URL of the listing (a string)long: The longitude of the listing (a float)lat: The latitude of the listing (a float)
Now that we have our models, let's start by writing some simple code
Setting up Selenium
I strongly suggest using a virtual environment to follow along
We can set up a selenium instance to crawl in python by using
from selenium.webdriver.chrome.service import Service
service = Service()
service.start()
driver = webdriver.Chrome()
list_url = // Your list url
driver.get(list_url)
time.sleep(5)
Crawling the Data
This simply code chunk is enough to navigate to your list url. All our crawler does thereafter is just
- Click on each item sequentially
- Navigate to the page that links to the item
- Extract the data from the page
- Go back to the original list url
So, before we can even start crawling, it's important to understand how many items we need to crawl. We can do so with a simple while loop
div_element = driver.find_element(
By.CSS_SELECTOR,
'div[class*="m6QErb"][class*="DxyBCb"][class*="kA9KIf"][class*="dS8AEf"]',
)
console.log(f"Starting to crawl list page : {list_url}")
# Scroll down to the specific div element
last_height = driver.execute_script("return arguments[0].scrollHeight", div_element)
while True:
driver.execute_script(
"arguments[0].scrollTo(0, arguments[0].scrollHeight)", div_element
)
time.sleep(2)
html_source = div_element.get_attribute("innerHTML")
curr_height = driver.execute_script("return arguments[0].scrollHeight", div_element)
if curr_height == last_height:
break
last_height = curr_heightThis simply checks the height of the div which contains all our saved items and sees if it has increased in size each time.
Once we navigate to a specific window, we can then extract all the data that we need.
We first try to find the parent element that contains the data on the listing page
def extract_details_from_window(driver, review: str) -> Listing:
try:
for _ in range(3):
try:
driver.find_element(
By.CSS_SELECTOR, 'div[class*="m6QErb WNBkOb"]:not(:empty)'
)
except Exception as e:
console.log(
"Unable to find parent element. Retrying again in 4 seconds..."
)
time.sleep(4)Once we've validated that we've found the parent element, we parse the content using Beautiful Soup 4.
parent_container = driver.find_element(
By.CSS_SELECTOR, 'div[class*="m6QErb WNBkOb"]:not(:empty)'
)
soup = BeautifulSoup(parent_container.get_attribute("innerHTML"), "html.parser")
is_empty = len(soup.contents) == 0
if is_empty:
console.log("Parent container is empty")
raise ValueError("Parent container is empty")In the event that we cannot find any content - this sometimes happens if we just cannot click the item succesfully. We simply raise an error and move on to the next item.
Once we've extracted the data, we can then extract the data from the page.
Here's an example of the logs for the data data that we extracted from the bearded bella page
[17:37:18] Unable to find parent element. Retrying again in 4 main.py:70
seconds...
Extracted review as It’s very good - the cold main.py:100
pasta is to die for and the coffee is solid. Solid
4/5 would go back
[17:37:24] Extracted out html from parent container crawl.py:37
Extracted title as Bearded Bella crawl.py:39
Extracted status as Open crawl.py:53
Extracted rating as 4.2 crawl.py:66
Extracted rating as 790 crawl.py:67
Extracted address as 8 Craig Rd, Singapore 089668 crawl.py:75
Extracted lat as 1.2777283 and long as 103.8428438 crawl.py:82
Extracted category as Restaurant crawl.py:96
Extracted hasDelivery as False crawl.py:97
Extracted hasTakeaway as True crawl.py:98
Extracted hasDineIn as TrueSaving the Data
Once we've extracted out the individual items, we can then write it to a csv file with
data = [i for i in data if i is not None]
csv_file = "items.csv"
with open(csv_file, "w", newline="", encoding="utf-8-sig") as file:
writer = csv.writer(file)
# Write the header row
writer.writerow(Listing.__fields__.keys())
# Write the data rows
for item in data:
try:
writer.writerow(item.dict().values())
except Exception as e:
print(f"An error occurred while extracting data: {str(e)}")
import pdb
pdb.set_trace()
Note that running this specific file will take you quite some time. I suggest running it in the background while you do other things since we implement a good amount of timeouts so we don't get rate limited.
Classification with GPT
Now that we have our data, we can go beyond just scraping the data and actually do something with it. In my case, I scrapped a total of ~86 different entries so I went ahead and manually rated them on a scale of 1-10.
This gives us a df with the following columns
> df.columns()
Index(['title', 'rating', 'number_of_reviews', 'address', 'review',
'hasDelivery', 'hasTakeaway', 'hasDineIn', 'category', 'status', 'url',
'long', 'lat', 'country'],
dtype='object')Most of the code here for classification was modified from the following tweet which you can check out here
Pydantic Models
As always, we start by defining a simplepydantic model to store our data for each individual restaurant
class Location(BaseModel):
title:str
rating:float
number_of_reviews:int
user_review:str
categories:list[str]We can then create a simple function to extract all of the data from our dataframe
locations = []
for row in df.itertuples():
location = Location(
title = row.title,
rating = row.rating/2,
number_of_reviews = row.number_of_reviews,
user_review=row.review,
categories = [row.category]
)
locations.append(location)
Yake-ing out the keywords
We first use use the Yake keyword extractor to extract out all the keywords that are present in our text
Yake is a light weight unsupervised automatic keyword extraction algorithm that uses a small set of heuristics to capture keywords. You can check it out here
We can install the library by running the following command
pip install git+https://github.com/LIAAD/yake
We can then use the following code to extract out the keywords
import yake
kw_extractor = yake.KeywordExtractor()
keywords = set([])
for row in df.itertuples():
formatted_string = f"title: {row.title}, review: {row.review}, category: {row.category}"
new_keywords = kw_extractor.extract_keywords(formatted_string)
extracted_keywords = [x[0] for x in new_keywords]
for extracted_keyword in extracted_keywords:
keywords.add(extracted_keyword)Since Yake is simply extracting out semantic bits which might have useful information, we end up with certain tags which aren't very useful. Here are some examples that don't really make sense
['AMAZING','AMAZING DUCK','AMAZING DUCK BREST']GPT Keywords
This is where GPT comes in. We basically get it to look at all our keywords and then generate ~30 categories that can convery the same meaning. If you look at my dataset in the github repo, you'll notice that there are also a good amount of non-english words.
I was a bit lazy to filter it so I decided to just tell GPT to only consider english categories.
python class Tags(BaseModel):
categories: List[str]
def generate_categories(keywords): keywords_with_new_lines = '\n'.join(keywords)
prompt = f"""
Invent categories for some restaurants. You are about to be provided with a brief description of a restrautn from google maps.
Here are some categories that we have. Only consider english categories.
{keywords_with_new_lines}
Create 30 short categories that semantically group these keywords.
Think step by step
"""
response = openai.ChatCompletion.create(
model = "gpt-3.5-turbo-16k",
messages = [
{'role':'user','content':prompt}
]
functions = [
{
'name': 'output_categories',
'description': 'The final list of categories',
'parameters':Tags.schema()
}
],
function_call={
'name':'output_categories'
}
)
parsed_json = response.choices[0]["message"]["function_call"]["arguments"]
categories = json.loads(parsed_json)["categories"]
return categories
res = generate_categories(list(keywords))
Since most of my user reviews had been rather sporadic and inconsistent in length, I thought it wouldn't be useful to force gpt to generate a lot of different recomendations but instead simply focus on a small set of categories - 30 seemed like a good number.
Categorising
Once we had our categories, we now need to categorise and assign categories to each individual item with .. gpt again.
@retry(tries=3, delay=2)
def location:Location,categories:list[str]):
joined_categories = '\n'.join(categories)
prompt = f"""
Given a Restaurant title and a candid user review, return a new list of 4 categories for the following restaurant
You can use the following categories
{joined_categories}
Restaurant Title: {location.title},
Existing Categories: [{','.join(location.categories)}]
User Review: {location.user_review}
You MUST only response with each chose category separated by a new line.
You MUST not say anything after finishing.
Your response will be used to tag the paper so don't say anything!
The 4 Categories:
""
response = openai.ChatCompletion.create(
model = "gpt-3.5-turbo-16k",
messages = [
{'role':'user','content':prompt}
]
)
return response["choices"][0]["message"]["content"].split("\n")
retry package which allows for automatic retries in case the API fails or the function throws an error. This is useful since the API can sometimes fail due to rate limits.
I'd like to also throw an error if a response takes too long but I haven't figured out how to do that yet.
Putting it all together
Once we've got the categorisation functionality down, all we need is to then work on the actual classification. We can do this by simply iterating through each restaurant and then tagging it with the categories that we generated earlier with ourtag_restaurant function.
We can do so with the following loop.
parsed_locations = []
for location in locations:
new_categories = tag_restaurant(location,categories)
new_location = location.copy()
new_location.categories.extend(new_categories)
unique_categories = list(
set(
[i.lower().strip() for i in new_location.categories]
)
)
new_location.categories = [i.title() for i in unique_categories]
parsed_locations.append(new_location)
before writing it to a csv with the following function
def write_locations_to_csv(locations: List[Location], file_name: str):
fieldnames = list(Location.schema()["properties"].keys())
with open(file_name, "w", newline='') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for location in locations:
writer.writerow(location.dict())
write_locations_to_csv(parsed_locations, "locations.csv")The results aren't honestly too bad - we can see from the quick screengrab that I took that it was able to accurately tag certain places correctly - the function sometime generated duplicate tags and so the use of a set in our code was useful to remove duplicates.
Building a UI
I used streamlit to build a quick UI for us to iterate through the different categories and see what the results were like.
import streamlit as st
import pandas as pd
from pydantic import BaseModel
from typing import List
df = pd.read_csv("./locations.csv")
parsed_categories = [[j.strip() for j in i[1:-1].replace("'", "").split(",")] for i in df["categories"].to_list()]
for cat_list in parsed_categories:
for cat in cat_list:
category_set.add(cat)
st.title("Location Filter")
# Filter by title
title_filter = st.sidebar.text_input("Search by title")
filtered_df = df[df["title"].str.contains(title_filter, case=False)]
# Filter by categories
unique_categories = list(category_set)
selected_categories = st.sidebar.multiselect("Filter by categories", unique_categories)
filtered_df = filtered_df[filtered_df["categories"].apply(lambda x: any(category in x for category in selected_categories) or len(selected_categories) == 0)]
print(unique_categories)
# Filter by number of reviews
min_reviews, max_reviews = st.sidebar.slider(
"Filter by number of reviews",
int(df["number_of_reviews"].min()),
int(df["number_of_reviews"].max()),
(0, int(df["number_of_reviews"].max())),
)
filtered_df = filtered_df[
(filtered_df["number_of_reviews"] >= min_reviews)
& (filtered_df["number_of_reviews"] <= max_reviews)
]
# view_df = filtered_df[["title", "number_of_reviews", "categories"]]
# Display the filtered DataFrame
st.write(filtered_df[["title", "number_of_reviews", "rating", "user_review"]])
This is what the UI looks like
